
Quando Claude Sonnet 4.5 è stato lanciato nel settembre 2025, ha infranto molti dei prompt esistenti. Non perché il rilascio fosse difettoso, ma perché Anthropic ha ricostruito il modo in cui Claude segue le istruzioni.
Le versioni precedenti deducevano le tue intenzioni ed espandevano su richieste vaghe. Claude 4.x ti prende alla lettera e fa esattamente ciò che chiedi, niente di più.

Per comprendere i nuovi metodi, abbiamo valutato 25 popolari tecniche di ingegneria degli input contro i documenti di Anthropic, esperimenti della comunità e implementazioni reali per scoprire quali input funzionano effettivamente meglio con Claude 4.x. Queste cinque tecniche
Cosa È Cambiato in Claude 4.5 Che Ha Interrotto I Prompt Esistenti?
I modelli Claude 4.5 danno priorità a istruzioni precise piuttosto che a supposizioni “utili”.
Le versioni precedenti completavano gli spazi vuoti per te. Se chiedevi una “dashboard,” si presumeva che tu volessi grafici, filtri e tabelle di dati.
Claude 4.5 ti prende alla lettera. Se chiedi una dashboard, potrebbe darti un quadro vuoto con un titolo perché non hai chiesto il resto.
Anthropic afferma chiaramente: “I clienti che desiderano un comportamento ‘oltre il dovuto’ potrebbero dover richiedere esplicitamente questi comportamenti.”
Allora, dobbiamo smettere di trattare il modello come una bacchetta magica e cominciare a trattarlo come un dipendente letterale.
Nessuna competenza di design. Nessun costruttore. Nessun problema. Solo risultati.
Inizia Ora
Le 5 Tecniche Provate Che Migliorano Misurabilmente Le Prestazioni Di Claude
Basandoci sulla nostra ricerca, queste cinque tecniche hanno costantemente portato miglioramenti evidenti nelle prestazioni di Claude per i compiti che gli abbiamo affidato.
1. Prompt Strutturati ed Etichettati
Il prompt di sistema di Claude Sonnet 4.5 utilizza prompt strutturati ovunque. Simon Willison ha esplorato i prompt di sistema e ha trovato sezioni avvolte in tag come <behavior_instructions>, <artifacts_info>, e <knowledge_cutoff>.
Infatti, potresti modificare “Styles” per vedere in azione il prompting strutturato di Anthropic.
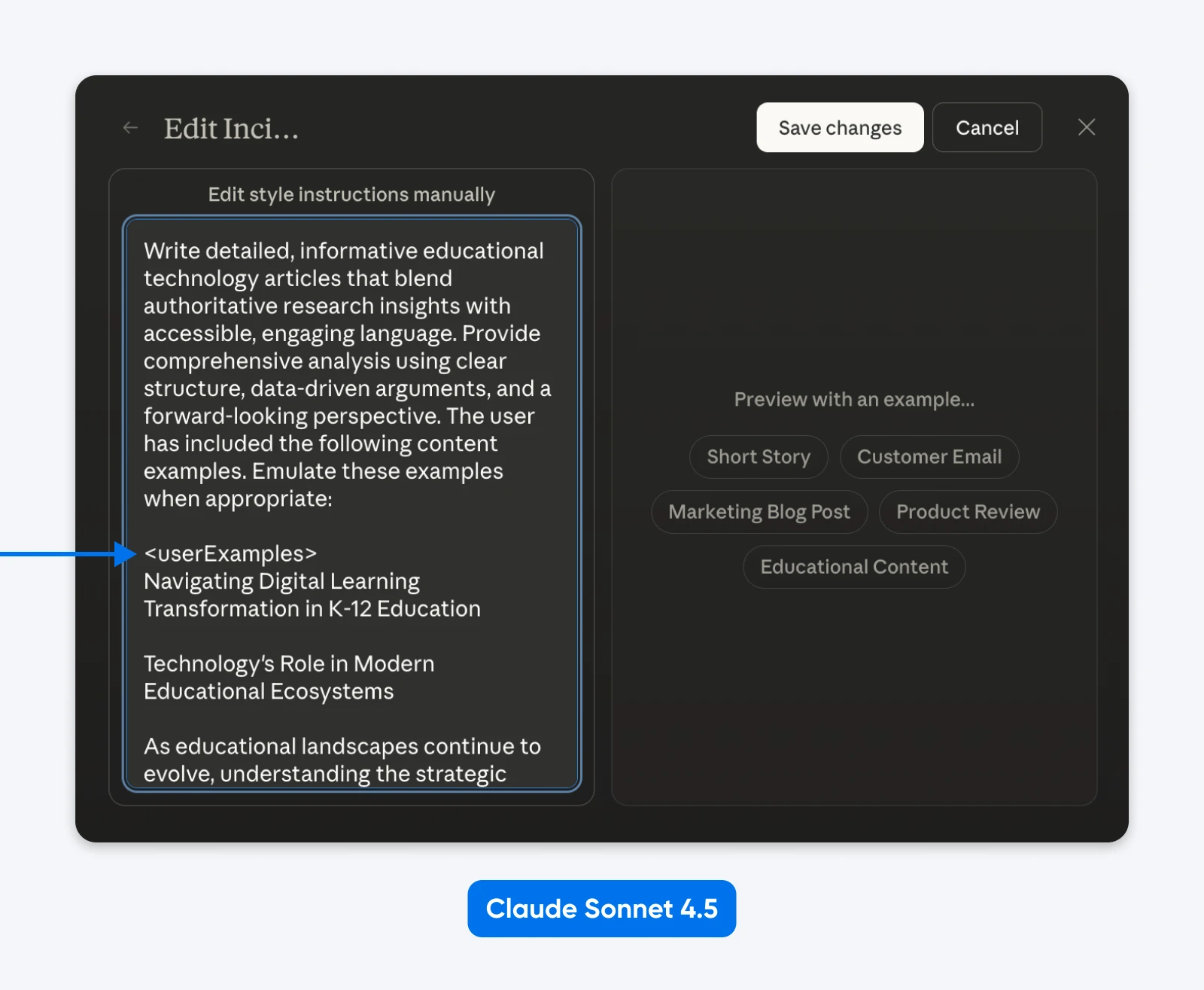
Quello che possiamo dedurre è che Claude è stato addestrato su prompt strutturati e sa come analizzarli. XML funziona bene, così come JSON o altri tipi di prompt etichettati.
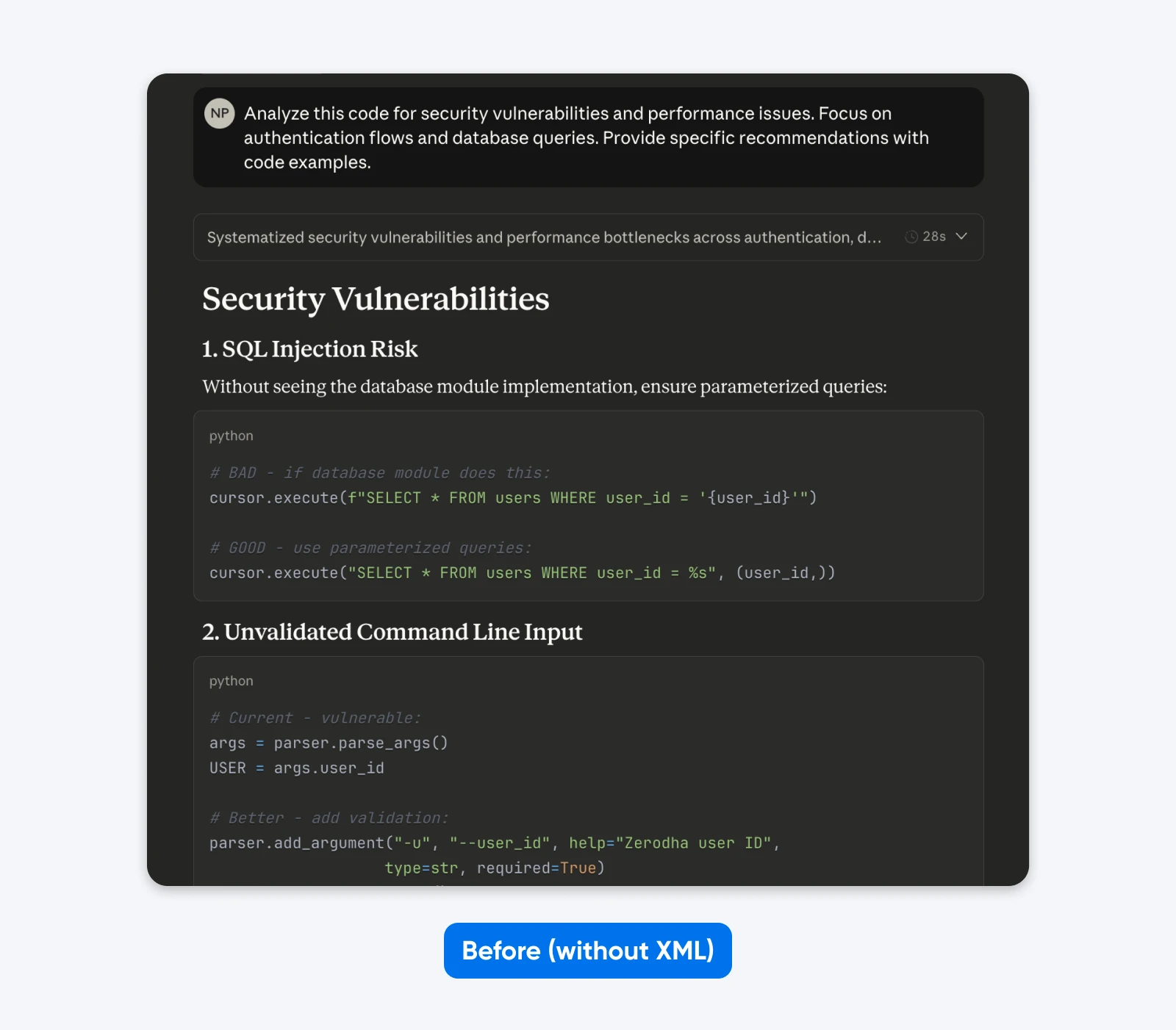
Prima:
Analizza questo codice per vulnerabilità di sicurezza e problemi di prestazione. Concentrati sui flussi di autenticazione e sulle interrogazioni al database. Fornisci raccomandazioni specifiche con esempi di codice.
Dopo (strutturazione del prompt):
<task>Analizza il codice fornito per problemi di sicurezza e prestazioni</task>
<focus_areas>
– Flussi di autenticazione
– Ottimizzazione delle query del database
</focus_areas>
<code>
[il tuo codice qui]
</code>
<output_requirements>
– Identifica specifiche vulnerabilità con valutazioni di gravità
– Fornisci esempi di codice corretti
– Prioritizza le raccomandazioni in base all’impatto aziendale
</output_requirements>
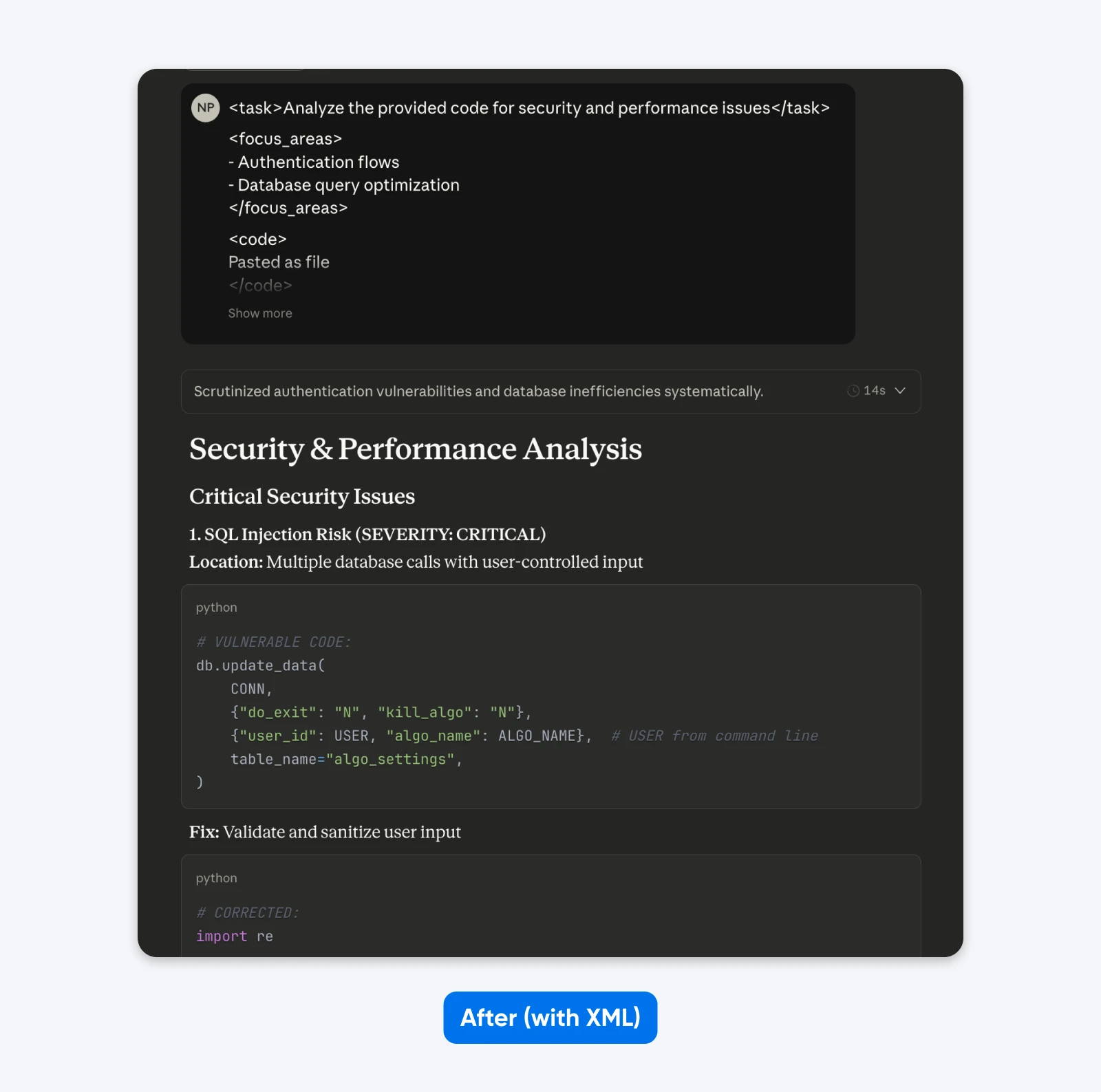
Se confronti questi risultati, noterai che il prompt strutturato fornisce un output con più contesto per aiutarti a capire e risolvere i problemi di sicurezza nel codice. Spiega il problema, indica cosa fa la correzione e poi fornisce la correzione del codice.
Formati Alternativi Che Funzionano:
JSON:
{
"task": "Rivedi il codice di autenticazione",
"focus_areas": ["Hash delle password", "Sicurezza delle sessioni", "Iniezione SQL"],
"context": "App di assistenza sanitaria, necessario HIPAA",
"output_format": "Rischio, impatto, correzione, gravità per vulnerabilità"
}
Intestazioni Chiare:
COMPITO: Esamina il codice di autenticazione per vulnerabilità
FOCUS: Hashing delle password, sessioni, iniezione SQL
CONTESTO: App di assistenza sanitaria che richiede conformità HIPAA
FORMATO DI OUTPUT: Rischio → Impatto HIPAA → Correzione → Gravità
Tutti e tre funzionano ugualmente bene.
Quando i prompt strutturati funzionano meglio:
- Componenti dell’invito multipli (task, contesto, esempi, requisiti)
- Input lunghi (più di 10.000 token di codice o documenti)
- Flussi di lavoro sequenziali con passaggi distinti
- Task che richiedono riferimenti ripetuti a sezioni specifiche
Quando saltare i prompt strutturati: Domande semplici dove il testo semplice funziona bene.
Valutazione dell’efficacia: 9/10 per compiti complessi, 5/10 per interrogazioni semplici.
2. Riflessione Estesa per Problemi Complessi
Il Pensiero Esteso offre miglioramenti significativi nei compiti di ragionamento complesso con un grande compromesso: la velocità.
L’annuncio di Claude 4 di Anthropic ha mostrato notevoli miglioramenti delle prestazioni con il pensiero esteso abilitato. Nella competizione di matematica AIME 2025, i punteggi sono migliorati significativamente.
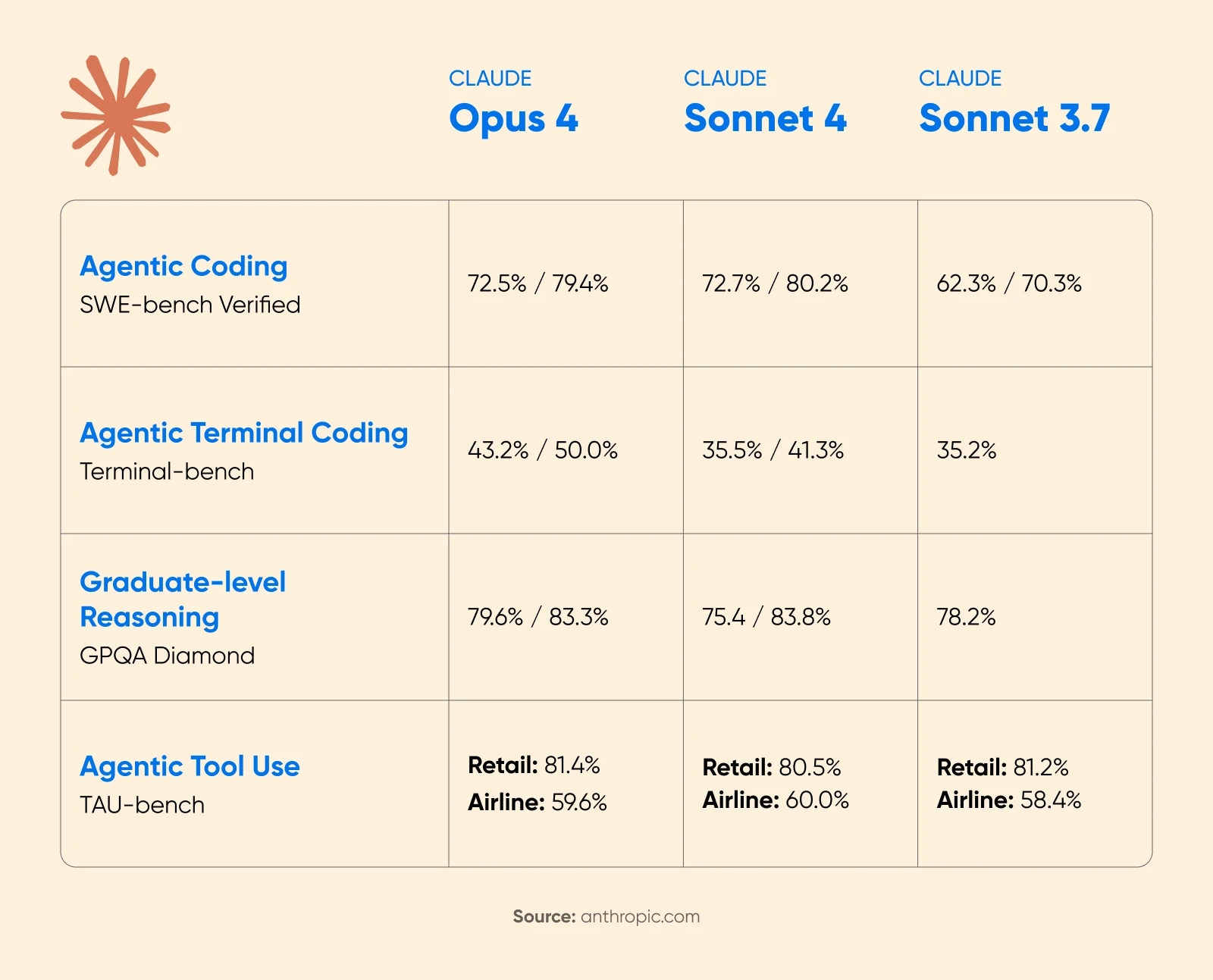
Cognition AI ha riportato un aumento del 18% nelle prestazioni di pianificazione con Sonnet 4.5, definendolo “il salto più grande che abbiamo visto da Claude Sonnet 3.6”.
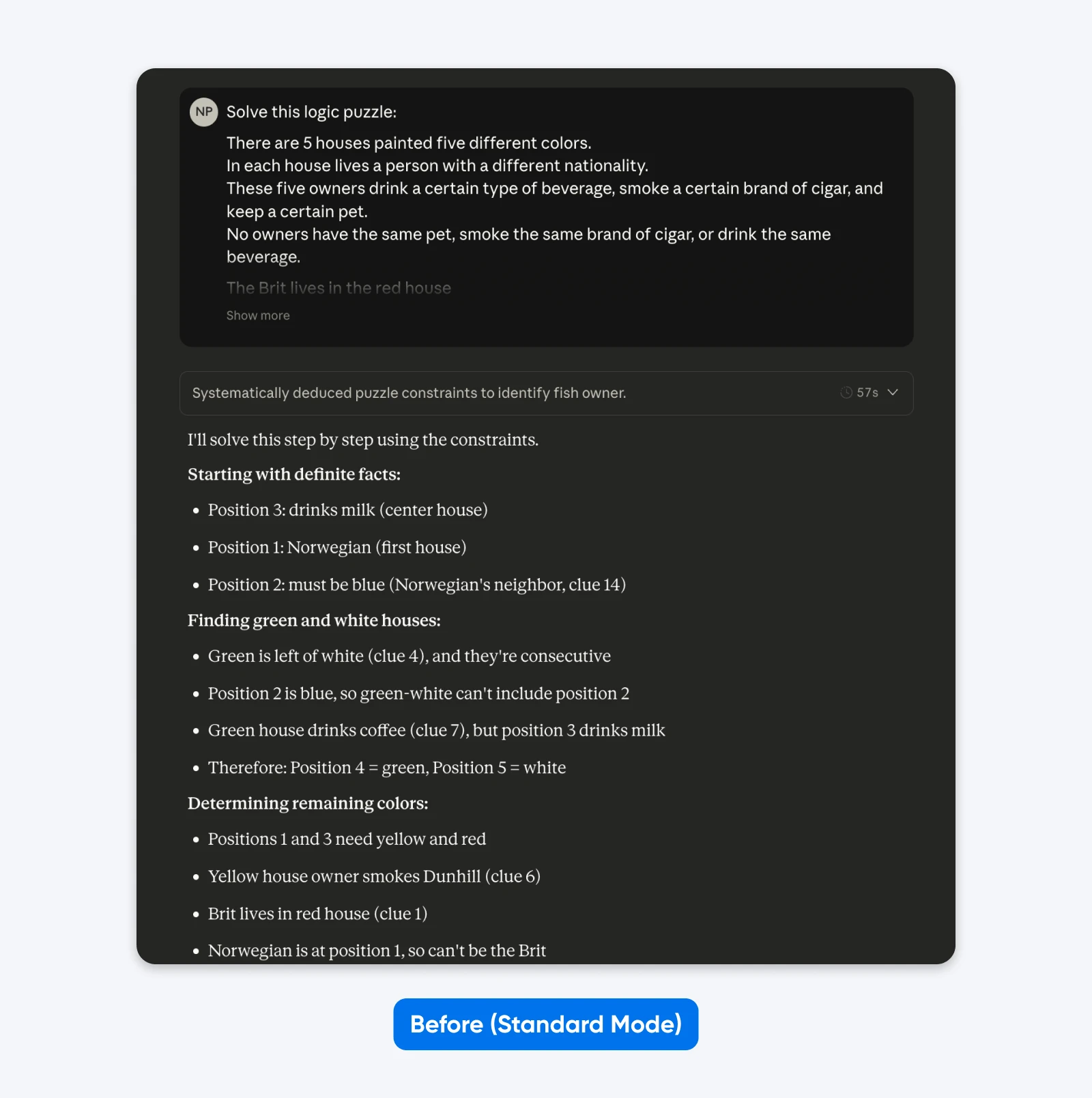
Prima (Modalità Standard):
Risolvi questo rompicapo logico: Cinque case in fila, ognuna di un colore diverso…
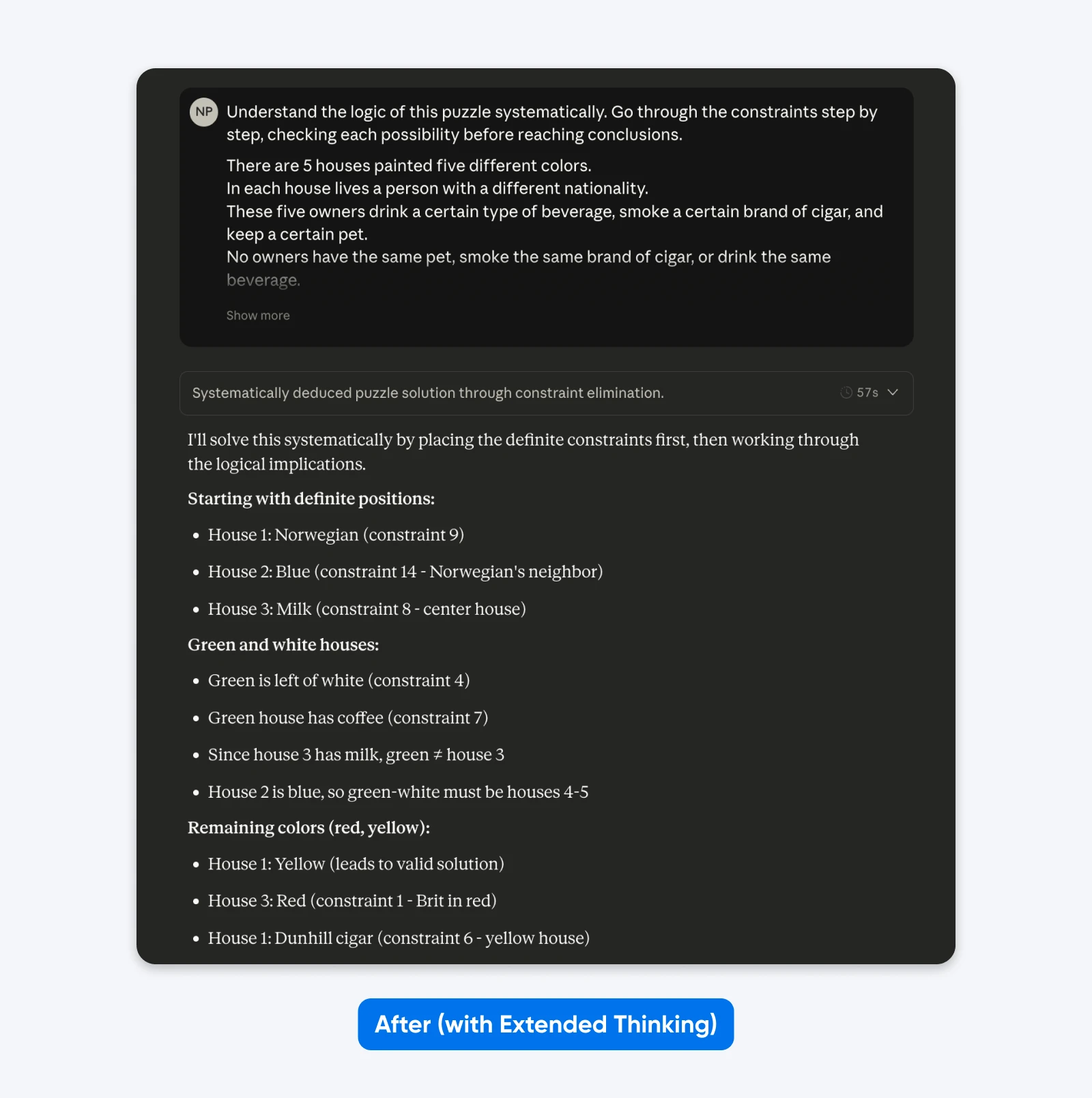
Dopo (con Riflessione Approfondita):
Comprendi la logica di questo rompicapo sistematicamente. Analizza i vincoli passo dopo passo, verificando ogni possibilità prima di arrivare a delle conclusioni.
Cinque case in fila, ognuna di un colore diverso…
Non noterai molta differenza con prompt semplici come quello sopra. Ma per problemi complessi e di nicchia (basi di codice personalizzate, pianificazione logica multi-step), la differenza diventa evidente.
Quando la cosa estesa funziona:
- Pianificazione logica multi-step che richiede verifica
- Ragionamento matematico con molteplici percorsi di soluzione
- Compiti di codifica complessi che abbracciano più file
- Situazioni in cui la correttezza è più importante della velocità
Quando Saltare: Iterazioni rapide, query semplici, scrittura creativa, compiti sensibili al tempo
Valutazione dell’efficacia: 10/10 per il ragionamento complesso, 3/10 per le query semplici.
3. Essere Brutalmente Specifici Riguardo I Requisiti
I modelli Claude 4 sono stati addestrati per seguire le istruzioni con maggiore precisione rispetto alle generazioni precedenti.
La documentazione di Anthropic dice:
“I modelli Claude 4.x rispondono bene a istruzioni chiare ed esplicite. Essere specifici riguardo all’output desiderato può aiutare a migliorare i risultati. I clienti che desiderano un comportamento ‘oltre le aspettative’ dai modelli precedenti di Claude potrebbero aver bisogno di richiedere questi comportamenti più esplicitamente con i modelli più recenti.”
La documentazione sottolinea inoltre che Claude è abbastanza intelligente da generalizzare dalla spiegazione quando fornisci un contesto sul motivo per cui esistono le regole piuttosto che limitarti a esporre comandi. Questo significa che fornire una giustificazione aiuta il modello ad applicare correttamente i principi in casi limite non coperti esplicitamente.
I test effettuati da 16x Eval hanno dimostrato che sia Opus 4 che Sonnet 4 hanno ottenuto un punteggio di 9,5/10 nelle attività TODO quando le istruzioni specificavano chiaramente i requisiti, il formato e i criteri di successo. I modelli hanno dimostrato notevoli capacità di concisione e di seguire le istruzioni.
Prima (aspettative implicite):
Crea una dashboard di analisi.
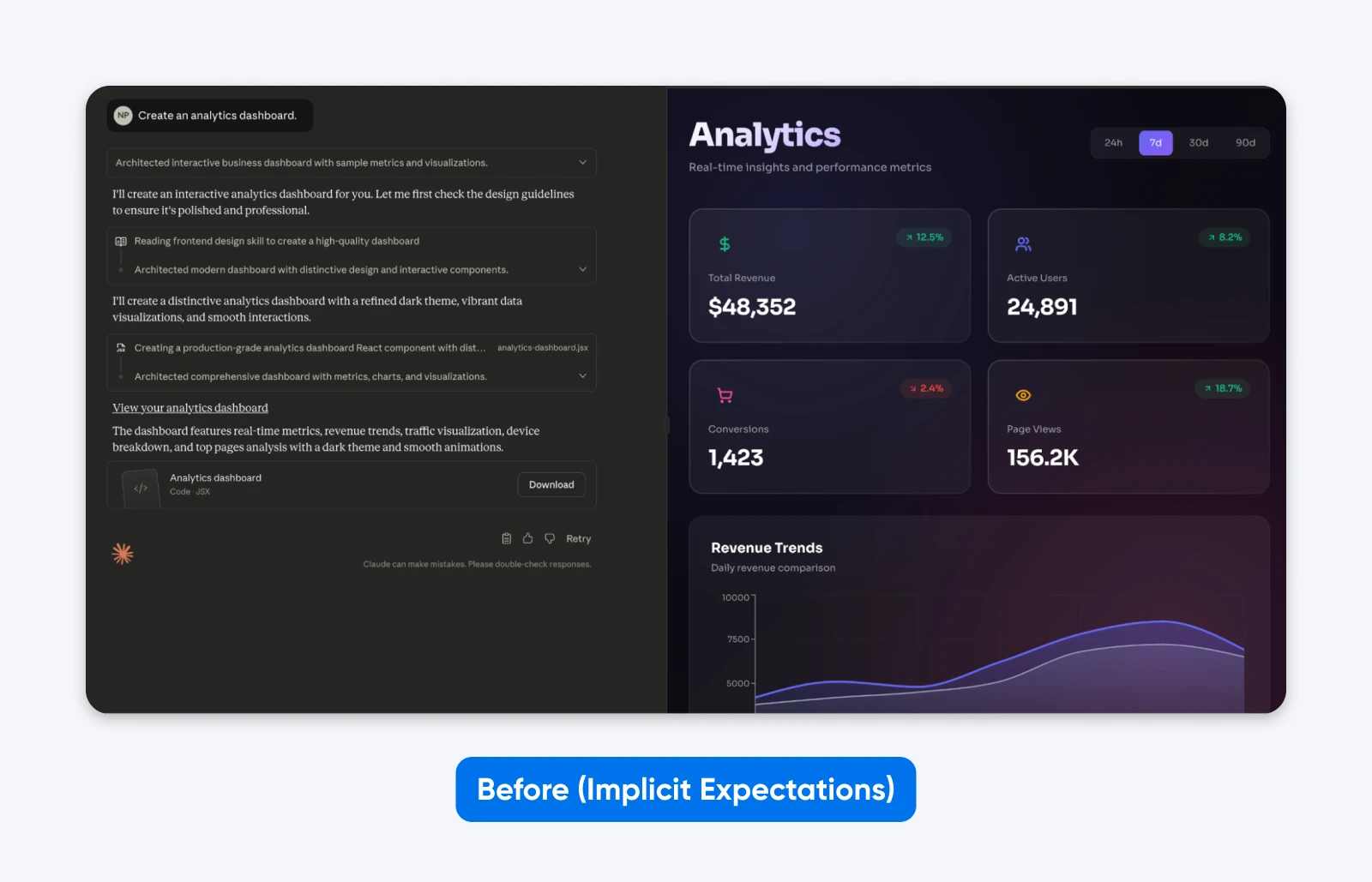
Noterai che questo risultato è ESATTAMENTE quello che abbiamo richiesto. Anche se Claude ha preso un po’ di libertà creativa nell’estetica, non ha alcuna funzionalità.
Dopo (requisiti espliciti):
Crea una dashboard di analisi. Includi quante più funzionalità e interazioni rilevanti possibile. Vai oltre il basilare per creare un’implementazione completamente caratterizzata con visualizzazione dei dati, capacità di filtraggio e funzioni di esportazione.
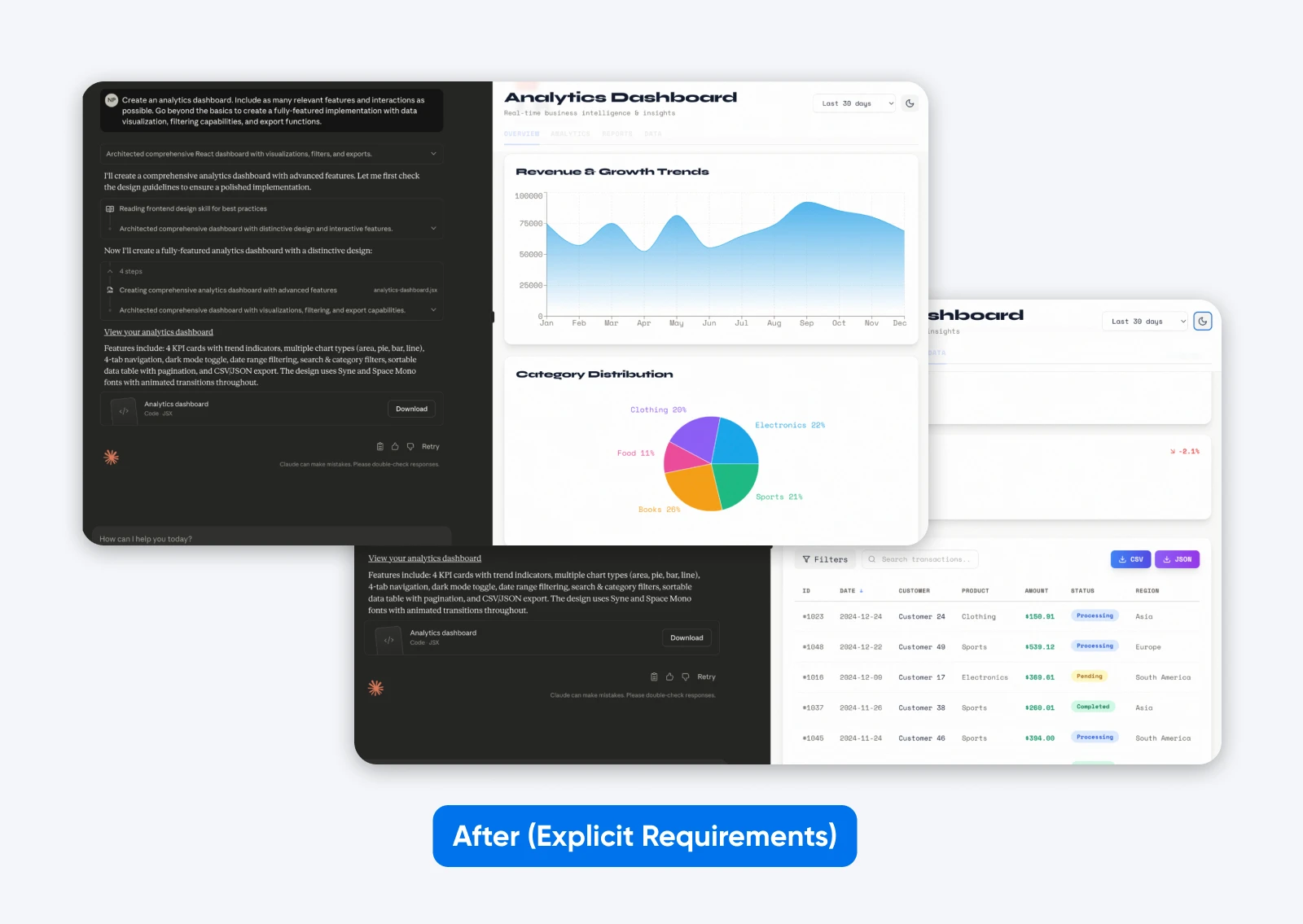
Questa seconda uscita con un prompt più descrittivo offre maggiori funzionalità, una dashboard basata su alcuni dati fittizi, che sono presentati sia graficamente che in formato tabellare, e dispone di schede per separare tutti i dati.
Ecco cosa fa essere specifici con l’ultimo Claude.
Per chiarire ulteriormente questo punto, ecco un altro esempio che mostra come il contesto migliori il seguire le istruzioni:
Prima (comando senza contesto):
NON usare mai le ellissi nella tua risposta.
Dopo (istruzione motivata dal contesto):
La tua risposta sarà letta ad alta voce da un motore di sintesi vocale, quindi evita le ellissi poiché il motore non saprà come pronunciarle.
Principi fondamentali per istruzioni esplicite:
- Definisci cosa significa “completo” per il tuo compito specifico: Non presumere che Claude inferirà gli standard di qualità.
- Spiega perché esistono le regole invece di limitarti a enunciarle: Claude generalizza meglio da istruzioni motivate.
- Specifica esplicitamente il formato di output: Richiedi “paragrafi di prosa” invece di sperare che Claude non scelga di default i punti elenco.
- Fornisci criteri di successo concreti: Come si presenta il completamento del compito?
Valutazione dell’efficacia: 9/10 per tutti i tipi di attività.
4. Mostra Esempi Di Ciò Che Desideri
Il few-shot prompting fornisce a Claude esempi di input e output che dimostrano il comportamento desiderato. Questo funziona, ma solo quando gli esempi sono di alta qualità e adatti al compito, e l’impatto varia notevolmente a seconda del caso d’uso.
La guida ufficiale di Anthropic sottolinea:
“I modelli Claude 4.x prestano molta attenzione ai dettagli e agli esempi come parte del loro preciso seguire le istruzioni. Assicurati che i tuoi esempi siano in linea con i comportamenti che vuoi incoraggiare e minimizzino i comportamenti che vuoi evitare.”
Anthropic raccomanda 3-5 esempi diversi e pertinenti per compiti complessi. Più esempi equivalgono a prestazioni migliori.
Ecco un esempio di come appare nella pratica:
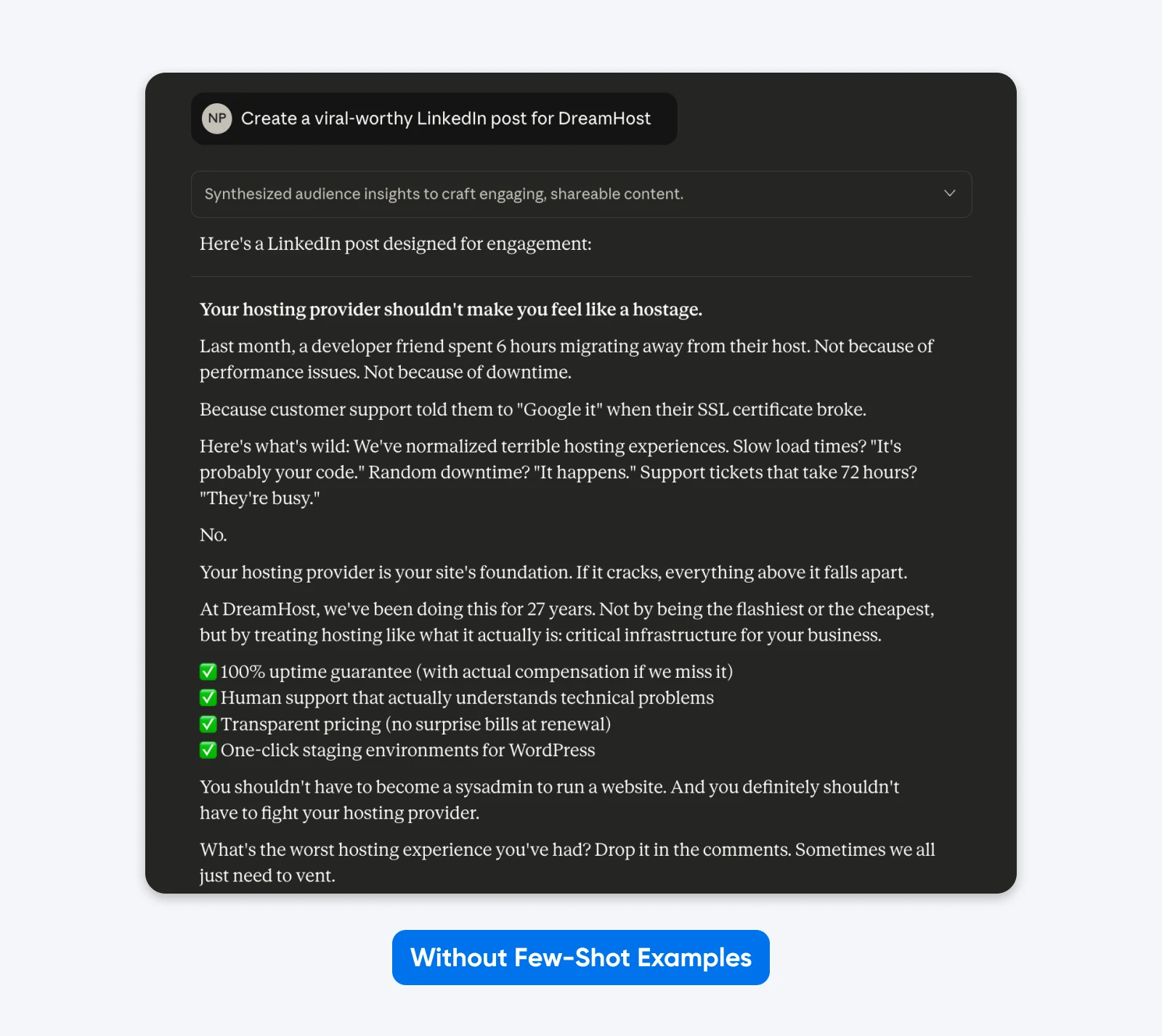
Qui, Claude ha preso la libertà creativa con il formato, l’uso degli emoji, il messaggio e il tono. Linguaggio aziendale generico
Aggiungere esempi funziona perché mostrano piuttosto che raccontare, chiarendo i requisiti sottili che sono difficili da esprimere solo attraverso la descrizione.
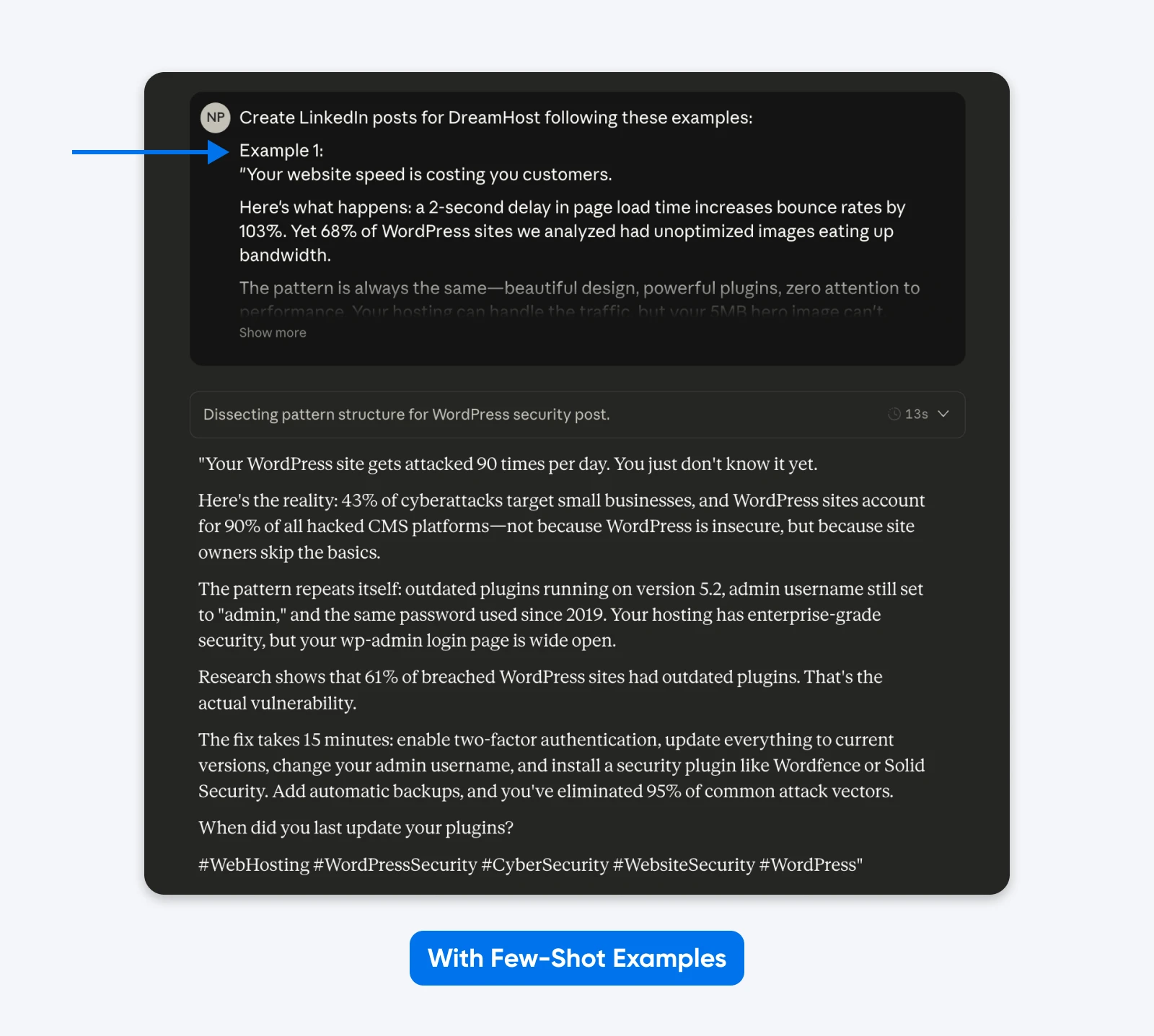
Questa uscita aderisce più strettamente agli esempi che ho fornito nel prompt. Puoi utilizzare il metodo degli esempi a pochi colpi per ottenere post su LinkedIn come quelli che hanno avuto più successo. Un articolo accademico su progettazione di Macchine a Stati Finiti (FSM) ha mostrato che gli esempi strutturati hanno raggiunto un tasso di successo del 90% rispetto alle istruzioni senza esempi.
Come Implementare:
- Racchiudi gli esempi nei tag <example>, raggruppati nei tag <examples>
- Posiziona gli esempi all’inizio del primo messaggio utente
- Utilizza 3-5 esempi diversi per compiti complessi
- Corrispondi ogni dettaglio negli esempi all’output desiderato (Claude 4.x replica convenzioni di denominazione, stile di codice, formattazione, punteggiatura)
- Evita esempi ridondanti
Quando Gli Esempi Funzionano Meglio:
- Formattazione dei dati che richiede una struttura precisa
- Modelli di codifica complessi che necessitano approcci specifici
- Compiti analitici che dimostrano metodi di ragionamento
- Output che richiede uno stile e convenzioni coerenti
Quando Saltare: Domande semplici dove bastano le istruzioni, o quando vuoi che Claude utilizzi il proprio giudizio.
Valutazione dell’efficacia: 10/10 per le attività di formattazione, 6/10 per le query semplici.
5. Metti Il Contesto Prima Della Tua Domanda
Claude ha una finestra di contesto di 200.000 token (fino a 1 milione in alcuni casi) e può comprendere le richieste posizionate ovunque nel contesto. Tuttavia, la documentazione di Anthropic consiglia di posizionare i documenti lunghi (più di 20.000 token) in cima ai prompt, prima delle richieste.
I test hanno dimostrato che questo migliora la qualità della risposta fino al 30% rispetto all’ordinamento basato sulla query, specialmente con input complessi e multi-documento.
Perché? I meccanismi di attenzione di Claude danno più peso ai contenuti verso la fine dei prompt. Posizionare la domanda dopo il contesto permette al modello di fare riferimento al materiale precedente mentre genera le risposte.
Prima (prima delle query):
Analizza le prestazioni finanziarie trimestrali e identifica le tendenze principali.
[20,000 token di dati finanziari]
Dopo (primo contesto):
[20,000 token di dati finanziari]
Basandoti sui dati finanziari trimestrali forniti sopra, analizza le prestazioni e identifica le tendenze principali nella crescita dei ricavi, nell’espansione del margine e nell’efficienza operativa. Concentrati su spunti operativi per le decisioni esecutive.
Quando è importante: Analisi di lungo contesto dove Claude necessita di fare riferimento estensivo a materiale precedente.
Quando Saltare: Prompt brevi sotto i 5.000 token.
Valutazione dell’efficacia: 8/10 per compiti a lungo contesto, 4/10 per prompt brevi.
Quali Tecniche Di Sollecitazione Non Funzionano Più: Sfatare I Miti Comuni
Le modifiche di Claude 4.5 hanno invalidato diverse tecniche popolari che funzionavano con i modelli precedenti.
1. Enfasi Sulle Parole (TUTTE MAIUSCOLE, “DEVI,” “SEMPRE”)
Scrivere tutto in maiuscolo non garantisce più la conformità. L’analisi di Chris Tyson ha scoperto che ora Claude dà priorità al contesto e alla logica piuttosto che all’enfasi.
Se scrivi “MAI fabbricare dati” ma il contesto implica la necessità di una stima, Claude 4.5 dà priorità al bisogno logico rispetto al tuo comando maiuscolo.
Usa la logica condizionale invece:
- Cattivo: Usa sempre numeri esatti!
- Buono: Se sono disponibili dati verificati, utilizza cifre precise. In caso contrario, fornisci intervalli e indicale come stime.
2. Istruzioni Manuali del Flusso di Pensiero
Dire al modello di “pensare passo dopo passo” spreca token quando si utilizza la modalità di Pensiero Esteso.
Quando abiliti il Pensiero Esteso, il modello gestisce il proprio budget di ragionamento. Aggiungere le tue istruzioni “passo dopo passo” è ridondante.
Cosa fare invece:
Fidati dello strumento. Se attivi il Pensiero Esteso, rimuovi tutte le istruzioni su come pensare.
3. Vincoli Negativi (“Non Fare X”)
Dire esattamente a Claude cosa non fare spesso si ritorce contro.
La ricerca sulle istruzioni “Pink Elephant” dimostra che dire a un modello avanzato di non pensare a qualcosa aumenta la probabilità che si concentri su di esso.
Il meccanismo di attenzione di Claude evidenzia il concetto proibito, mantenendolo attivo nella finestra di contesto.
Invece, trasforma ogni negativo in un comando positivo:
- Cattivo: Non scrivere introduzioni lunghe e prolisse. Non usare parole come “approfondire” o “tessuto.”
- Buono: Inizia direttamente con l’argomento principale. Usa un linguaggio conciso e incisivo.
Come Migrare I Prompt Da Claude 3.5 A Claude 4?
Se stai migrando da Claude 3.5 a 4.5, puoi migrare la tua libreria di prompt seguendo cinque passaggi sistematici validati dall’esperienza degli sviluppatori.
Useremo uno scenario di hosting comune per questo esempio. L’obiettivo è generare una risposta del supporto tecnico per un cliente che sta riscontrando un errore “503 Service Unavailable” sul suo sito WordPress.

1. Verifica delle Ipotesi Implicite
Inizia identificando dove il prompt si affida al modello per indovinare il contesto. Nelle versioni precedenti, il modello avrebbe dedotto che stavi utilizzando lo stack software più comune. Claude 4.5 non farà quel salto.
Prompt Precedente:
“Il mio sito web si carica lentamente e mostra degli errori. Sei un esperto amministratore di server. Pensaci passo dopo passo e dimmi come correggere la configurazione per renderlo più veloce.”
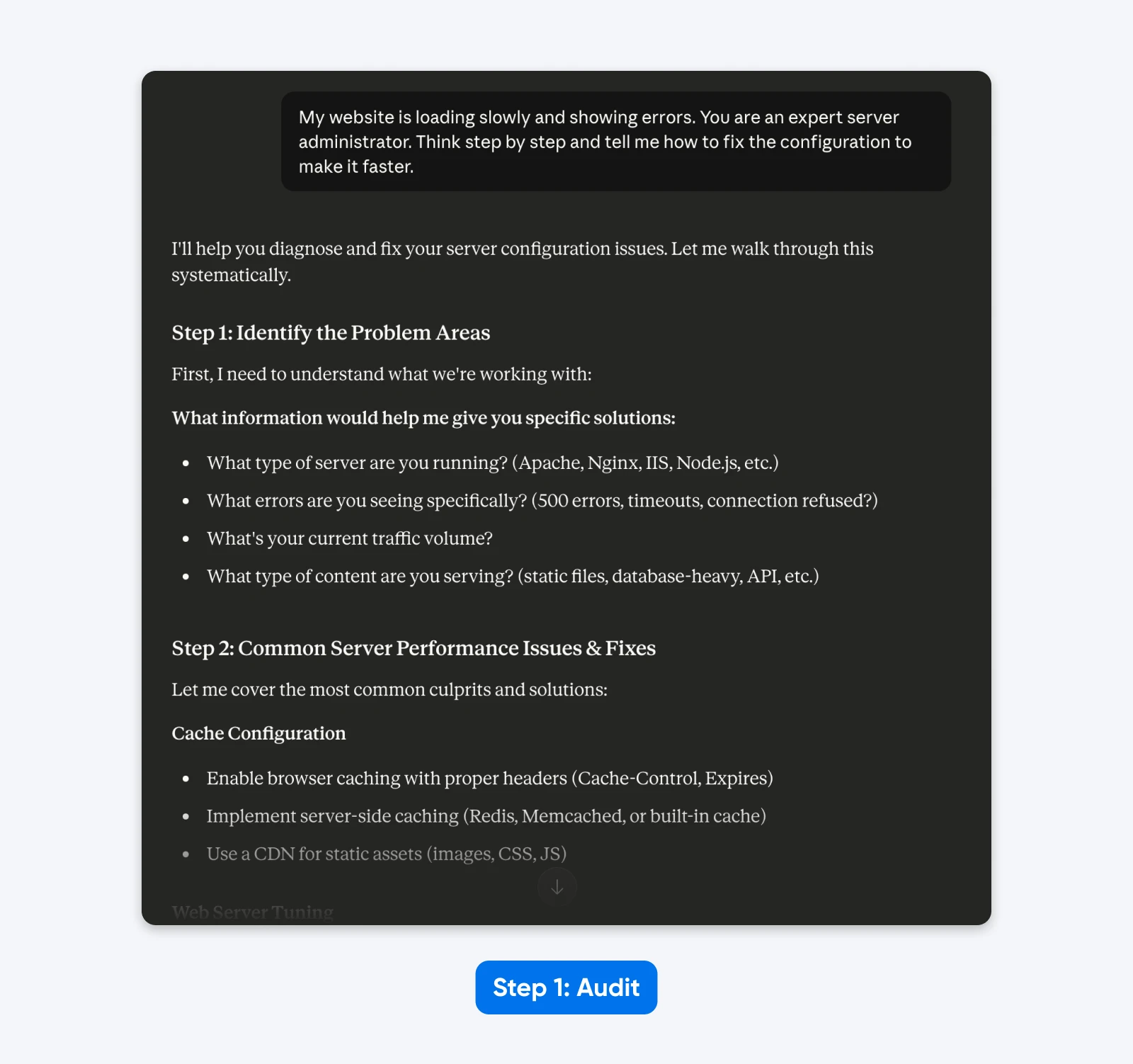
L’Audit:
- “Sito web” implica una configurazione generica piuttosto che un CMS specifico (WordPress).
- “Lentamente” è soggettivo; potrebbe significare un alto Tempo al Primo Byte o un rendering lento delle risorse.
- “Errori” manca dei codici di stato HTTP specifici necessari per la diagnosi.
- “Amministratore di server esperto” e “Pensare passo dopo passo” sono istruzioni di guida non necessarie.
Nella risposta, Claude 4.5 chiede ulteriori informazioni perché è programmato per evitare di fare supposizioni.
2. Rifattorizzazione per Specificità Esplicita
Ora, riscrivi il prompt per definire l’ambiente, il problema specifico e il formato di output desiderato. Devi fornire i dettagli tecnici che il modello aveva precedentemente ipotizzato.
Prompt Rielaborato:
“Il mio sito WordPress in esecuzione su Nginx e Ubuntu 20.04 sta riscontrando un alto Tempo al Primo Byte (TTFB) ed errori occasionali 502 Bad Gateway. Sei un esperto amministratore di server. Pensa passo dopo passo e fornisce modifiche specifiche alla configurazione di Nginx e PHP-FPM per risolvere questi timeout.”

Il Risultato: Il prompt ora specifica esattamente lo stack software (Nginx, Ubuntu, WordPress) e l’errore specifico (502 Bad Gateway), riducendo la possibilità di consigli irrilevanti riguardo Apache o IIS. E Claude risponde con un’analisi e una soluzione passo dopo passo.
3. Implementa La Logica Condizionale
Claude 4.5 eccelle quando gli viene fornito un albero decisionale. Invece di chiedere una singola soluzione statica, istruisci il modello a gestire diversi scenari in base ai dati che analizza.
Prompt con Logica:
“Il mio sito WordPress su Nginx e Ubuntu 20.04 sta riscontrando un TTFB elevato e errori 502 Bad Gateway. Sei un esperto amministratore di server. Pensa passo dopo passo.
Se i log degli errori mostrano ‘upstream sent too big header’, fornisci modifiche alla configurazione per le dimensioni dei buffer. Se i log degli errori mostrano ‘upstream timed out’, fornisci modifiche alla configurazione per i limiti di tempo di esecuzione.”
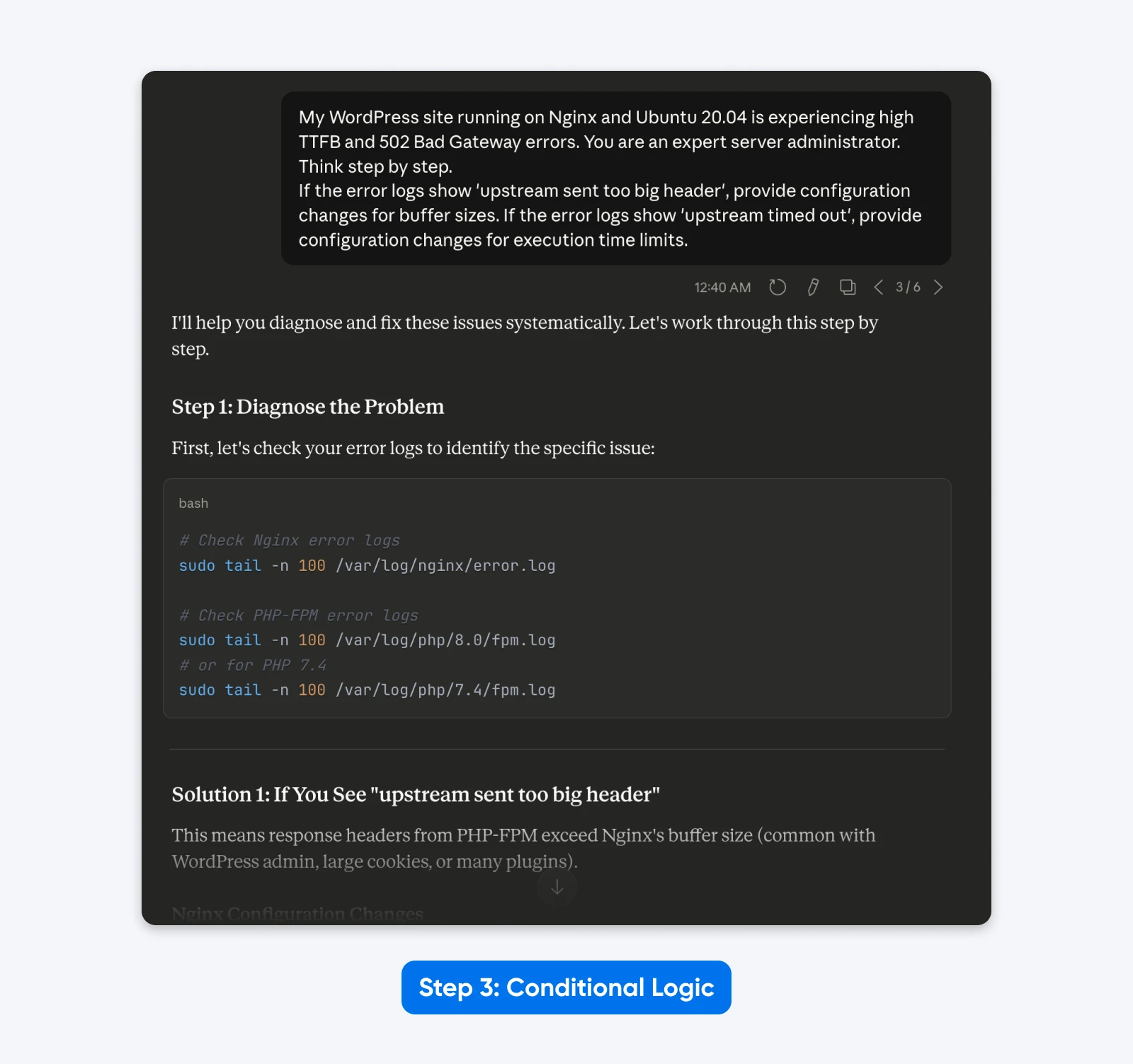
Il Risultato: L’output diventa dinamico. Il modello offre soluzioni mirate basate sulla logica della causa principale specifica che hai definito, piuttosto che un elenco generico di soluzioni.
4. Rimuovi Il Linguaggio Di Navigazione Obsoleto
I prompt legacy contengono spesso istruzioni di pensiero che gli utenti ritenevano migliorassero le prestazioni. Queste sono superflue e ridondanti con Claude 4.5 poiché ha un pensiero esteso.
Prompt Pulito:
“Il mio sito WordPress che funziona su Nginx e Ubuntu 20.04 sta riscontrando un alto TTFB e errori 502 Bad Gateway.
Se i log degli errori mostrano ‘upstream sent too big header’, fornisci modifiche alla configurazione per le dimensioni del buffer. Se i log degli errori mostrano ‘upstream timed out’, fornisci modifiche alla configurazione per i limiti di tempo di esecuzione.”
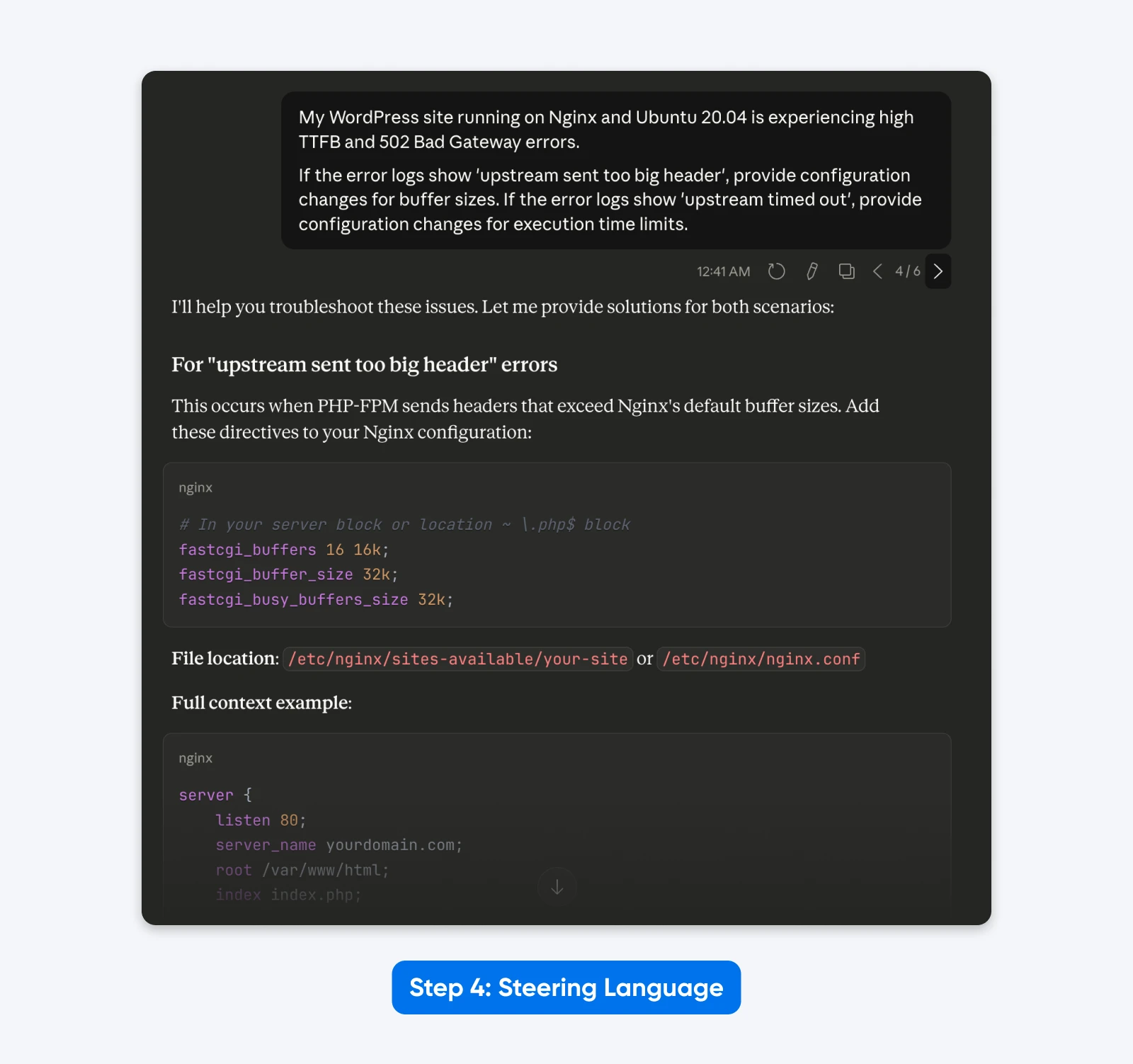
Il Risultato: Un prompt più snello che si concentra esclusivamente sul compito tecnico, eliminando la distrazione di “Sei un esperto” e “Pensa passo dopo passo”.
5. Testa Sistematicamente
Assembla i componenti in un formato strutturato usando XML o intestazioni chiare. Questo corrisponde ai dati di addestramento del modello e produce i risultati più consistenti.
RUOLO: Amministratore di Sistema Linux specializzato in prestazioni Nginx e WordPress.
COMPITO: Risolvere gli errori 502 Bad Gateway e ridurre il Time to First Byte (TTFB) per un sito WordPress su Ubuntu 20.04.
LOGICA:
- Se i log mostrano 'upstream sent too big header', aumentare fastcgi_buffer_size e fastcgi_buffers.
- Se i log mostrano 'upstream timed out', aumentare fastcgi_read_timeout in nginx.conf e request_terminate_timeout in www.conf.
REQUISITI DI OUTPUT:
- Fornire le linee esatte di configurazione da modificare.
- Spiegare l'impatto di ogni modifica sulla memoria del server.
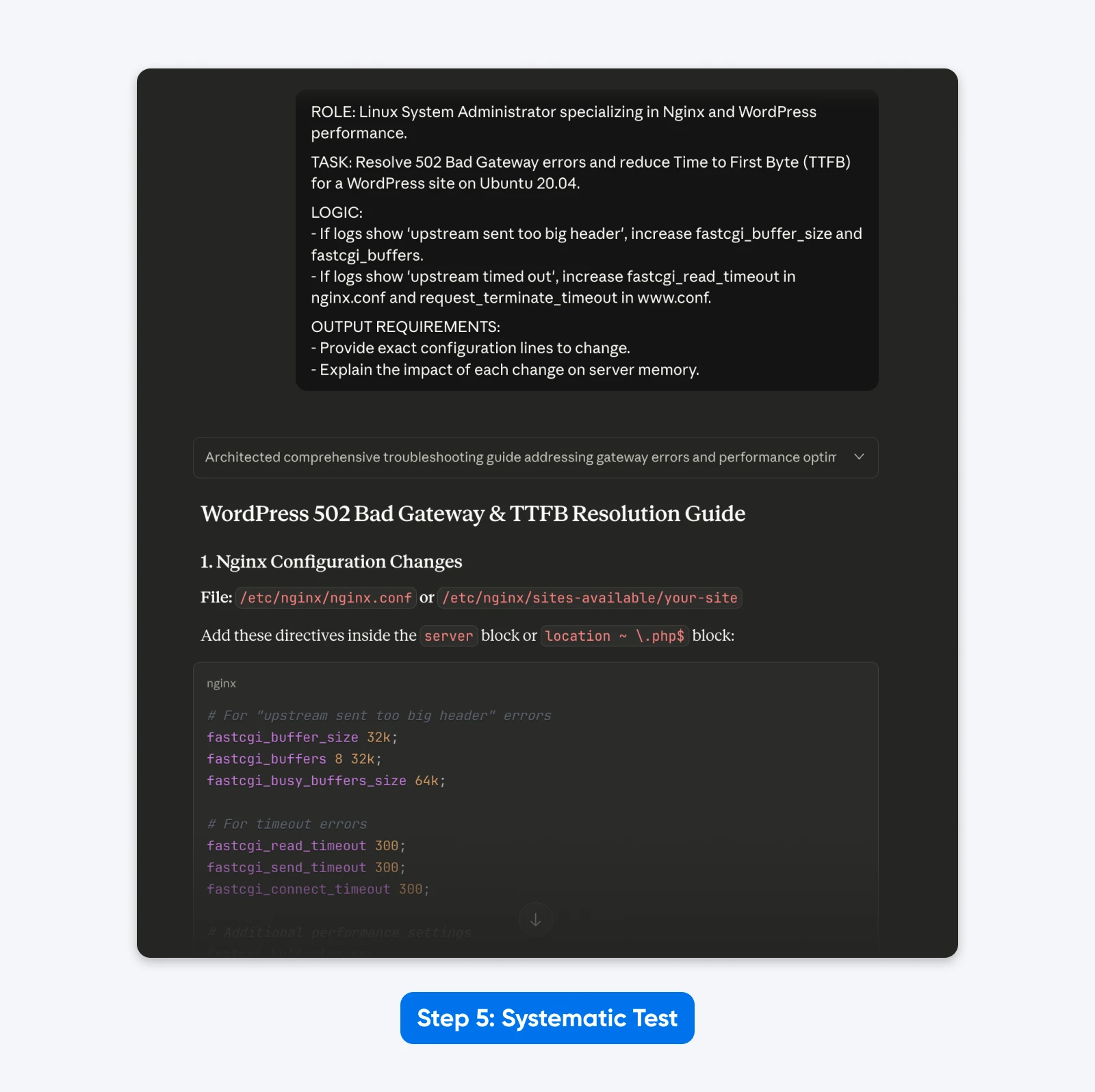
Il Risultato: La risposta è stata più strutturata, mi ha permesso di risolvere il problema con dati di configurazione copiabili e incollabili come richiesto e ha spiegato meglio la soluzione.
Cosa Significa Questo Per Il Tuo Flusso Di Lavoro
I modelli Claude 4.x funzionano diversamente dai modelli precedenti. Seguono le tue istruzioni esatte invece di supporre cosa intendevi, il che aiuta quando hai bisogno di risultati coerenti. Lo sforzo che impieghi nell’ingegneria dei prompt all’inizio si ripagherà se esegui lo stesso compito ripetutamente.
Ogni tecnica in questa guida è stata scelta accuratamente perché si allinea strettamente con il modo in cui è stato costruito Claude 4.x. I tag XML, la modalità di Pensiero Esteso, istruzioni esplicite, esempi a pochi colpi e un approccio basato sul contesto funzionano perché, basandosi sulle guide di sollecitazione di Claude e su prove aneddotiche, è probabile che sia così che Anthropic ha addestrato i modelli.
Allora vai avanti, scegli una o due tecniche da questa guida e testale sui tuoi flussi di lavoro effettivi. Misura quali cambiamenti e quali metodi funzionano a tuo favore. L’approccio migliore è quello supportato da dati reali provenienti dai tuoi flussi di lavoro quotidiani.

